Altos Web Solutions, inc. – 5725 Bravo Ave, Reno, NV 89506 USA
Home » Data Science
Data science continues to evolve as one of the most promising and in-demand career paths for skilled professionals. Today, successful data professionals understand that they must advance past the traditional skills of analyzing large amounts of data, data mining, and programming skills. In order to uncover useful intelligence for their organizations, data scientists must master the full spectrum of the data science life cycle and possess a level of flexibility and understanding to maximize returns at each phase of the process.
source: ischoolonline.berkeley.edu
Hadoop Performance
Predictive modeling, a component of predictive analysis, is a statistical process used to predict future outcomes or events using historical or real-time data. Businesses often use predictive modeling to forecast sales, understand customer behavior and mitigate market risks. It is also used to determine what historical events are likely to occur again in the future. Predictive modeling solutions frequently use data mining technologies to analyze large sets of data. Common steps in the predictive modeling process include gathering data, performing statistical analysis, making predictions, and validating or revising the model. These processes are repeated if additional input data becomes available.
source: techrepublic.com
Grounded in the principle of “never trust, always verify,” zero trust is designed as a response to the outdated assumption that everything inside of an organization’s network can be implicitly trusted. Traditional layers of security assume users and data are always operating within the confines of the enterprise walls and data centers — like a physical store. But today’s enterprises have users and partners working from anywhere and accessing applications and data deployed across data centers and external clouds — like an online store.
source: techrepublic.com
Address verification cleans and standardizes address data against an authoritative address database. Address verification software corrects spelling errors, formats information, and adds missing ZIP codes to incomplete or inaccurate physical addresses.
reference: dataladder.com
whether it’s a deliverable address. Address validation tools typically use authoritative databases such as the United States Postal Service (USPS) or Canada Post to run these comparisons.
address, improve the quality of your data and increase conversions? Well, you can with Loqate. Watch our short video to learn more about international address validation.
used effectively, can help to limit fraud and charge-backs. AVS works to verify that the billing address entered by the customer is the same as the one associated with the cardholder’s credit card account.
of Address is often requested when opening a bank account or other government account to confirm residence, help Know Your Customer (KYC) compliance and prevent fraudulent activities.
reference:
g2.com
loqate.com
Data cleansing is a process by which a computer program detects, records, and corrects inconsistencies and errors within a collection of data.
Data cleansing, also referred to as data scrubbing, is the process of removing duplicate, corrupted, incorrect, incomplete and incorrectly formatted data from within a dataset. The process of data cleansing involves identifying, removing, updating and changing data to fix it. The objective of data cleansing is to make reliable, consistent and accurate data available throughout the data lifecycle.
source: techrepublic.com
Step 1: Remove irrelevant and duplicate data
Step 2: Fix formatting and structural errors
Step 3: Filter outliers
Step 4: Address missing data
Step 5: Validate data
Step 6: Report results to appropriate stakeholders
One of the challenges of data cleansing is that it can be time-consuming, especially when pinpointing issues across disparate data systems. One of the best ways to make data cleansing more efficient is to use data cleansing tools.
There are a variety of data cleansing tools available in the market, including open source applications and commercial software. These tools include a variety of functions to help identify and fix data errors and missing information. Vendors, such as WinPure and DataLadder, offer specialized tools that focus solely on data cleansing tasks. And some data quality management tools, such as Datactics and Precisely, also offer helpful features for data cleansing.
The core features of data cleansing tools include data profiling, batch matching, data verification and data standardization. Some data cleansing tools also offer advanced data quality checks that monitor and report errors while processing data. There are also workflow automation features offered by some data cleansing tools that automate the profiling of incoming data, data validation and data loading.
Deduplication refers to a method of eliminating a dataset’s redundant data. In a secure data deduplication process, a deduplication assessment tool identifies extra copies of data and deletes them, so a single instance can then be stored.
Data deduplication software analyzes data to identify duplicate byte patterns. In this way, the deduplication software ensures the single-byte pattern is correct and valid, then uses that stored byte pattern as a reference. Any further requests to store the same byte pattern will result in an additional pointer to the previously stored byte pattern.
source: druva.com
reference: dataladder.com
Data literacy refers to the ability to read, understand, communicate, analyze and derive information from data, all while putting it into proper context. Forbes defines data literacy as using “data effectively everywhere for business actions and outcomes.”
Data literacy is a set of skills and knowledge used to find, understand, evaluate and create data.
With data literacy skills, employees better understand how company data works and how they can use it, allowing them to be more effective and streamline processes for the organization.
With the growing importance of data literacy in organizations and the abundance of data, there is increased emphasis on establishing data literacy training programs and appointing chief data officers to continuously assess and improve data literacy in the organization.
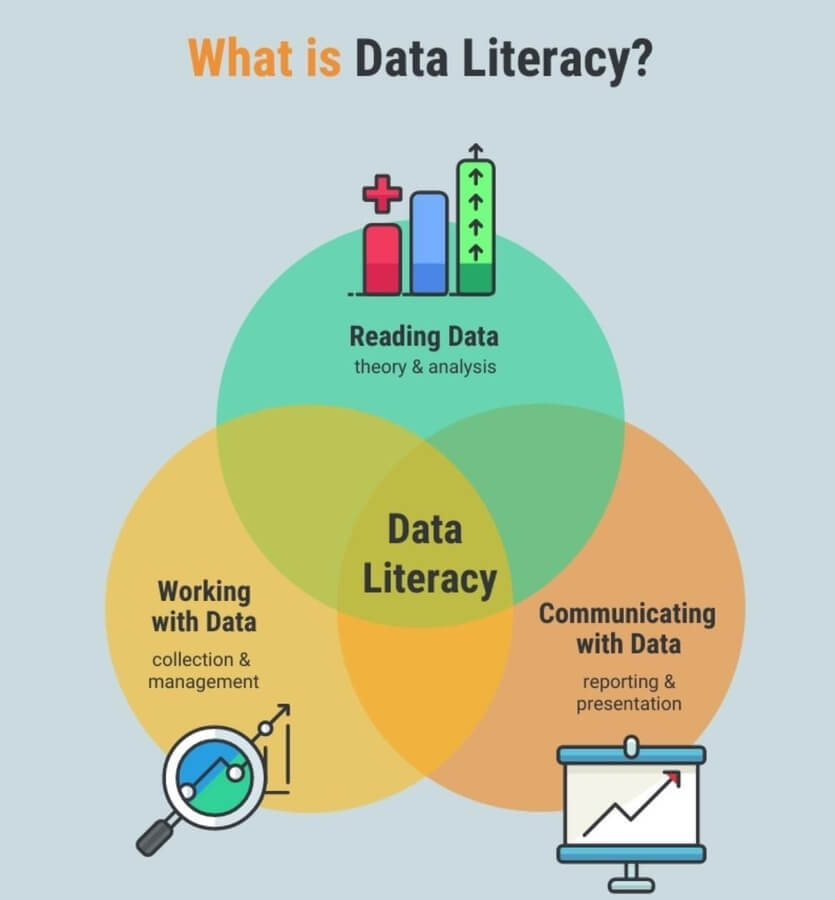
source: techrepublic.com
source: techrepublic.com
Data masking is a way to create a fake, but a realistic version of your organizational data. The goal is to protect sensitive data, while providing a functional alternative when real data is not needed—for example, in user training, sales demos, or software testing.
Data masking processes change the values of the data while using the same format. The goal is to create a version that cannot be deciphered or reverse engineered. There are several ways to alter the data, including character shuffling, word or character substitution, and encryption.
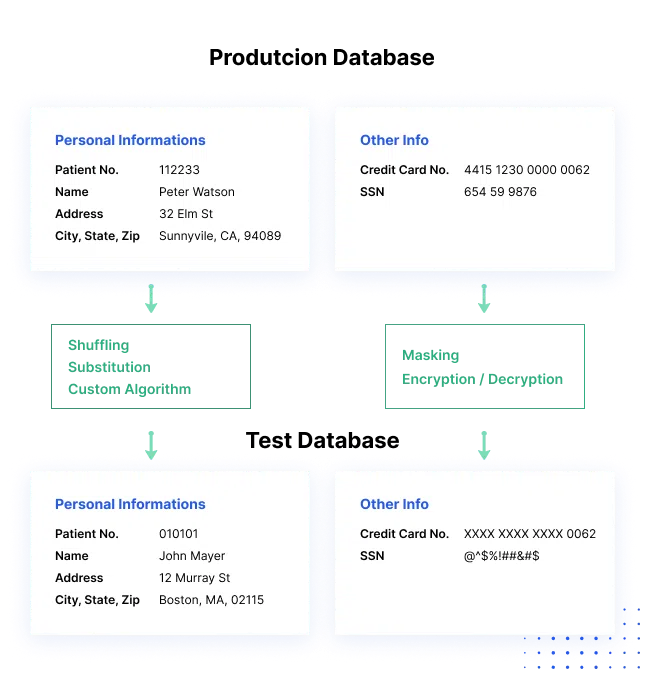
source:
magedata.ai
imperva.com
“The act of permanently replacing sensitive data at rest with a realistic fictional equivalent for the purpose of protecting data from unwanted disclosure.”
Industry analysts characterize SDM as a must-have data protection layer capable of protecting large swaths of data within an organization.
How organizations use static data masking
Copying sensitive data into misconfigured or unsecured testing environments happens more frequently than organizations would like to admit.
By using SDM, organizations can provide high-quality fictional data for the development and testing of applications without disclosing sensitive information. The more realistic the SDM tool can make the sensitive data, the more effective development and testing teams can be in identifying defects earlier in their development cycle. SDM facilitates cloud adoption because DevOps workloads are among the first that organizations migrate to the cloud. Masking data on-premises prior to uploading it to the cloud reduces the risk for organizations concerned with cloud-based data disclosure.
Organizations also use SDM to anonymize data they use in analytics and training as well as to facilitate compliance with standards and regulations (such as GDPR, PCI, HIPAA, etc.) that require limits on sensitive data that reveals personally identifiable information (PII).
In practical terms, SDM makes sensitive data unsensitive because it applies data transformations as it makes a realistic looking database copy. If an attacker compromises a non-production, statically masked database, the sensitive data might look like real data, but it isn’t. SDM does not slow down or change the way an application using the data will work because it applies SDM on all data up-front, so there is no impact once the masked database is made available to the various functions. SDM dramatically simplifies the securing of non-production data, because all sensitive data has been replaced, so there is no need to implement fine-grained object-level security.
source: imperva.com

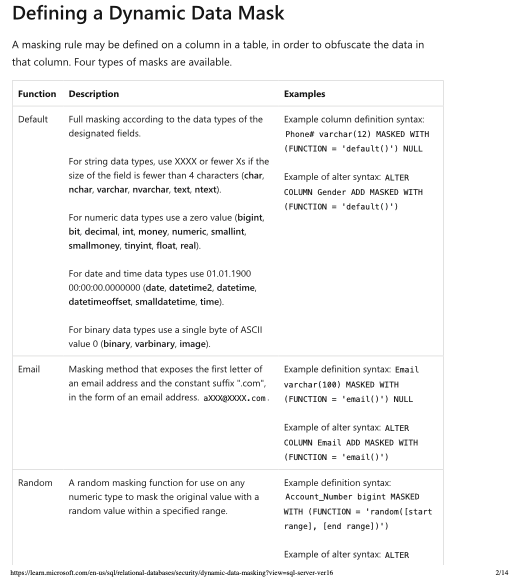
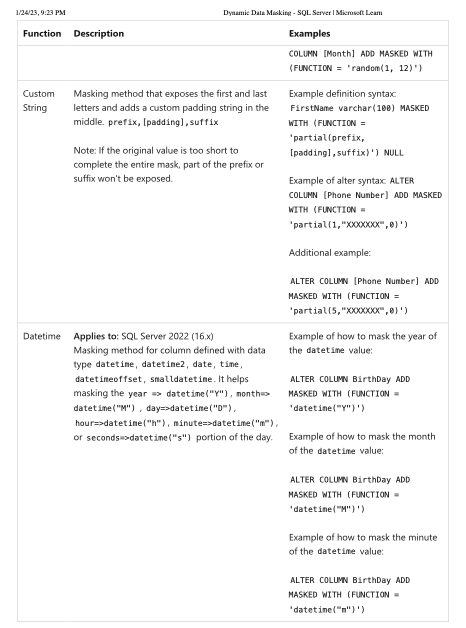
source: learn.microsoft.com
we use Microsoft & Talend visual studio
learn.microsoft.com
Other players
imperva.com
magedata.ai
source: builtin.com
reference
The Best Data Analytics Software of 2023
source: forbes.com
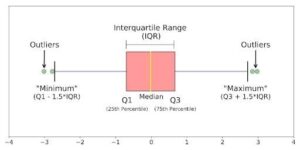
Boxplots can tell you about your outliers and what their values are. It can also tell you if your data is symmetrical, how tightly your data is grouped and if and how your data is skewed.
WHAT IS A BOXPLOT?
A boxplot is a standardized way of displaying the distribution of data based on a five number summary (“minimum”, first quartile [Q1], median, third quartile [Q3] and “maximum”). It can tell you about your outliers and what their values are. Boxplots can also tell you if your data is symmetrical, how tightly your data is grouped and if and how your data is skewed.
source: builtin.com
Tableau Is Business Intelligence Software that Helps People See and Understand Their Data. Your Eureka Moments are Waiting. Visualize Your Data in Minutes with Tableau. Business Analytics. Drag & Drop Reporting. Data Analysis. Business Intelligence. Data Discovery. Visual Analytics. Business Dashboards. Self-Service-BI. Mobile An
source: tableau.com
source: reference.com
Data quality is a measurement of company data that looks at metrics such as consistency, reliability, completeness and accuracy. The highest levels of data quality are achieved when data is accessible and relevant to what business users are working on.
Evaluation criteria:
source: techrepublic.com
source: techrepublic.com
What is unstructured data?
Unstructured data is a heterogeneous set of different data types that are stored in native formats across multiple environments or systems. Email and instant messaging communications, Microsoft Office documents, social media and blog entries, IoT data, server logs and other “standalone” information repositories are common examples of unstructured data.
Unstructured data may sound like a complicated scattering of unrelated information, not to mention a nightmare to analyze and manage, and it does take data science expertise and specialized tools to make use of this information, but despite the complexity of working with and making sense of unstructured data, this data type offers some significant advantages to companies that learn how to use it.
How to analyze unstructured data
source: techrepublic.com
Typical Data Quality by Attribute
Data Validation KPMs
source: globalz.com
Key data quality metrics to consider
source: techrepublic.com
source: hbr.org
What are the business costs or risks of poor data quality?
source: techrepublic.com
source: gartner.com
What is Talend Data Quality?
Talend Data Quality is one of the most popular solutions for business data quality purposes. It offers a wide range of data profiling, cleaning, standardization, matching and deduplication features. The solution is part of the greater Talend Data Fabric product, with a suite of solutions that also includes data integration, data integrity and governance, and application and API integration services.
Key features of Talend Data Quality
Pros of Talend Data Quality
Cons of Talend Data Quality
source: techrepublic.com
What is data integration?
Data integration is a framework that combines data from siloed sources to provide users with a unified vision. Data integration benefits include better data governance and quality, increased visualization, better decision-making, and better performance. Standardizing data is essential for data integration to be successful, as multiple teams — some of which may not have advanced IT technical knowledge and skills — need to access and use the data system.
When combined with tools like machine learning and predictive analysis, unified data insights can significantly impact a company’s operations, allowing it to detect risks in advance, meet compliance across the board, boost sales and detect new growth opportunities. Data integration aims to create a single access point of data storage that is available and has good quality standards. But to move data from one system to another and meet big data challenges with excellence requires a data integration strategy.
source: techrepublic.com
1) Make Smarter Business Decisions
2) Deliver Improved Customer Experiences
3) Cost Reduction
4) Increased Revenue Potential
5) Increased Innovation
6) Improved Security
7) Improved Collaboration
Data Integration Use-cases in Real World
1) Retail
Data integration can be used to track and manage inventory levels across multiple retail locations or channels, such as online and brick-and-mortar stores. This can help retailers ensure that they have the right products in stock at the right time and place, reducing the risk of lost sales due to out-of-stock items.
2) Marketing
Data integration can be used to combine customer data from various sources, such as social media interactions, website activity, and email campaigns, to create more detailed and accurate customer profiles. This can help marketers segment their audience more effectively and target their campaigns to specific groups of customers.
3) Finance
Data integration can help financial institutions improve risk management, fraud detection, and compliance efforts. Accordingly, this can help financial institutions identify new business opportunities and optimize their products and services according to the pricing plans.
4) Telecommunications
By integrating data from various sources, such as customer interactions, demographic information, and usage data, telecommunications companies can gain a 360-degree understanding of deeper understanding of their customers and their needs. This can help them to tailor their products and services to better meet the needs of their customers, leading to improved customer satisfaction.
5) Rating Services
Data integration can help rating services improve the accuracy and timeliness of their ratings by integrating data from multiple sources. For example, by integrating data from financial statements, market data, and news articles, rating services can gain a more complete view of a company’s financial performance and risk profile, which can help them provide more accurate and timely ratings.
6) Healthcare
Integrating patient data from various sources can help healthcare providers make more informed treatment decisions and improve patient care and outcomes. By having access to a more comprehensive view of a patient’s medical history, including past treatments and diagnoses, allergies, and medications, healthcare providers can make more informed treatment decisions and avoid potential adverse reactions or complications.
source: hevodata.com
With massive amounts of data being generated, the rapid pace of tech innovation, the costs of change, growing sprawl of application and data silos, and a plethora of available data management and analytics tools to choose from – it’s easy to see why so many businesses wrestle with trying to effectively manage and glean real value from their data.
Data that is not integrated remains siloed in the places it resides. It takes a lot of time and effort to write code and manually gather and integrate data from each system or application, copy the data, reformat it, cleanse it, and then ultimately analyze it. Because it takes so long to do this, and skilled resources in IT who can do it are scarce, the data itself may easily be outdated and rendered useless by the time the analysis is complete. Businesses don’t have time to wait anymore.
source: snaplogic.com
source: snaplogic.com
So, how do you do data integration? There are several approaches ranging from manual integration to low- code data integration platforms:
source: snaplogic.com
Developing a strategy for integrating data across your organization helps ensure that everyone has access to the most up-to-date data in a secure way. This article provides an example of a strategy you can use to develop your own.
The first step in data integration is not to acquire the tools and tech from vendors but to plan the company’s strategy. Data integration is not about data and technology — these are just tools that serve a purpose. Data integration is about collaboration between people, teams and your entire workforce.
Every company has its objectives and goals and must understand which data will help them achieve them. Aligned with a company’s mission, values and data governance strategy, data leaders must lead the data integration strategy.
Once organizations have answered what business goals their data integration needs to support, they can turn to other questions. Access and availability need to be clear and transparent. While executives and critical stakeholders might need full access and visibility on all unified data, other departments require restricted access. Additionally, roles and responsibilities should also be set.
Ideally, organizations should aim to integrate independent systems into one master data warehouse. In order to accomplish this task, leaders need to ask what data needs to be place: on the cloud, on-premises or hybrid. integrated, who will make up the data integration team and where will the data integration take place: on the cloud, on-premises or hybrid.
sources & references: techrepublic.com
If you’re considering using a data integration platform to build your ETL process, you may be confused by the terms data integration vs. ETL. Here’s what you need to know about these two processes.
Businesses have a wealth of data at their disposal, but it is often spread out among different systems. This scenario makes it challenging to get a clear picture of what’s happening in the business.
That’s where data integration and ETL — or Extract, Transform and Load — come in to support greater data visibility and usability. Although these two concepts are closely related, data integration and ETL serve distinct purposes in the data management lifecycle.
How are data integration and ETL similar?
However, it’s important to note that not all data integration solutions use ETL tools or concepts. In some cases, it’s possible to use alternative methods such as data replication, data virtualization, application programming interfaces or web services to combine data from multiple sources. It all depends on the specific needs of the organization if ETL will be the most useful form of data integration or not.
How are data integration and ETL different?
The main difference between data integration and ETL is that data integration is a broader process. It can be used for more than just moving data from one system to another. It often includes:
Data quality: Ensuring the data is accurate, complete and timely.
Defining master reference data: Creating a single source of truth for things like product names and codes and customer IDs. This gives context to business transactions.
source: techrepublic.com
In the past, data integration was primarily done using ETL tools. But, in recent years, the rise of big data has led to a shift towards ELT — extract, load and transform tools. ELT is a shorter workflow that is more analyst-centric and that can be implemented using scalable, multicloud data integration solutions.
These solutions have distinct advantages over ETL tools. Third-party providers can produce general extract-and-load solutions for all users; data engineers are relieved of time-consuming, complicated and problematic projects; and when you combine ETL with other cloud-based business applications, there is broader access to common analytics sets across the entire organization.
In the age of big data, data integration needs to be scalable and compatible with multicloud. Managed services are also becoming the standard for data integration, because they provide the flexibility and scalability that organizations need to keep up with changing big data use cases. Regardless of how you approach your data integration strategy, make sure you have capable ETL/data warehouse developers and other data professionals on staff who can use data integration and ETL tools effectively.
Data integration trends to watch in 2022
The proliferation of remote and online work maximizes workforce potential for companies but spreads data thin from platform to platform. From customer relationship management software to cloud services, data for your business could be hosted in multiple locations, leading to disorganization, data set errors and poor decision-making.
Companies are increasingly recognizing the problems that come with disparate data platforms and are leaning into data integration solutions. In this article, we cover some of the top data integration trends we’re seeing today and where they could lead in the future.
source: techrepublic.com
Talend helps organizations deliver healthy data to correctly inform their decision-making. The company provides a unified platform to support data needs without limits in scale or complexity. With Talend, organizations can execute workloads seamlessly across cloud providers or with on-premises data. Talend’s data integration solutions enable users to connect all their data sources into a clean, comprehensive and compliant source of truth.
Key differentiators
Con: Talend may suffer from performance and memory management issues.
Hevo is an end-to-end data pipeline platform that enables users to effortlessly leverage data. Hevo can pull data from multiple sources into warehouses, carry out transformations and offer operational intelligence to business tools. It is purpose-built for the ETL, ELT and Reverse ETL needs of today and helps data teams to streamline and automate data flows. Common benefits of working with Hevo include hours of time saved per week, accelerated reporting, and optimized analytics and decision-making.
Key differentiators
Con: The tool could benefit from more detailed documentation for first-time users to smoothen the learning curve.
Informatica Cloud Data Integration provides a fast and reliable way to integrate and deliver data and analytics to businesses. It is an intelligent data platform that continuously assesses the performance of processing engines and workload variations, all while enabling users to identify the correct data integration pattern for their use cases. With Informatica Cloud Data Integration, users can connect hundreds of applications and data sources on-premises and integrate data sources at scale in the cloud.
Key differentiators
Con: Users cannot store metadata locally with Informatica Cloud Data Integration.
Oracle Data Integrator is a thorough data integration platform that covers data integration requirements like high-volume, high-performance batch loads; SOA-enabled data services; and event-driven, trickle-feed integration processes. Oracle also provides advanced data integration capabilities to users that seek to implement seamless and responsive Big Data Management platforms through Oracle Data Integrator for Big Data.
Key differentiators
Con: Oracle’s solution involves a complex development experience in comparison to competitors.
Dataddo is a no-code platform for data integration, transformation and automation that seeks to provide users with complete control and access to their data. The platform works with many online data services, including existing data architectures users already have. Dataddo syncs dashboarding applications, data lakes, data warehouses and cloud-based services. It also visualizes, centralizes, distributes and activates data by automating its transfer from source to destination.
Key differentiators
Con: The platform can be quite confusing to new users.
Integrate.io is a low-code data warehouse integration platform that supports informed decision-making for data-driven growth. Its platform offers organizations capabilities to integrate, process and prepare data for analytics on the cloud. Integrate.io’s platform is scalable to make sure that organizations can make the most of big data opportunities without a hefty investment in software, hardware and staff. The platform gives companies the chance to enjoy instant connectivity to multiple data sources and a rich set of out-of-the-box data transformations.
Key differentiators
Con: The tool could benefit from more advanced features and customization.
IRI Voracity is an end-to-end data lifecycle management platform that leverages technology to tackle speed, complexity and cost issues in the data integration market. It is an integration platform as a service (IPaaS) data integration tool that is ideal for quick and affordable ETL operations. IRI Voracity also offers data quality, masking, federation and MDM integrations.
Key differentiators
Con: The IRI product names may be confusing to users.
zigiwave.com
Zigiwave is a company that aims to disrupt the integrations industry, particularly where connections between applications are characterized by lines of code and a lot of time invested. Zigiwave’s product, ZigiOps, is a highly flexible no-code integration platform that creates powerful integrations in a handful of minutes. ZigiOps empowers non-technical users to carry out integration tasks in a few clicks without having to add scripts.
Key differentiators
Con: Since the company is based in Europe, the support time coverage may prove to be a challenge for users outside of Europe.
source: techrepublic.com
We use talend.com
A data lake is a set of unstructured information that you assemble for analysis. Deciding which information to put in the lake, how to store it, and what to make of it are the hard parts.
The concept of a data lake is perhaps the most challenging aspect of information management to understand. A data lake can be thought of not as something you buy, but as something you do. “Data lake” sounds like a noun, but it works like a verb.
James Dixon, chief technology officer of Hitachi-owned Pentaho, is credited with coining the term data lake in 2008. Dixon said he was looking for a way to explain unstructured data.
Data mart and data warehouse were existing terms; the former is generally defined as a department-level concept where information is actually used, and the latter is more of a storage concept. He began to think about metaphors with water: thirsty people get bottles from a mart, the mart gets cases from a warehouse, and the warehouse obtains and bottles it from the wild source — the lake.
source: techrepublic.com
Nik Rouda said the most common mistake in data lake projects is that companies don’t have the right people to manage it. Database administrators may not understand how to apply their knowledge to unstructured information, while storage managers typically focus on nuts and bolts. The people most affected by a data lake are probably those who pull the purse strings, because a company will need to budget for hiring analytic experts or outsourcing that job to a professional services organization.
source: techrepublic.com
Moving data from one location to another is the simple concept behind data migration. It is described as a shift of data from one system to another, characterized by a change in database, application or storage. Data migration may result from a need to modernize databases, build new data warehouses and/or merge new data from sources, among other reasons.
Key features for data migration
Popular data migration tools include:
source: techrepublic.com
we use talend.com
source: techrepublic.com
Data consistency means that each user sees a consistent view of the data, including visible changes made by the user’s own transactions and transactions of other users.
What is data consistency?Data consistency is one of ten dimensions of data quality. Data is considered consistent if two or more values in different locations are identical. Ask yourself: Is the data internally consistent? If there are redundant data values, do they have the same value? Or, if values are aggregations of each other, are the values consistent with each other?
What are some examples of inconsistent data?Imagine you’re a lead analytics engineer at Rainforest, an ecommerce company that sells hydroponic aquariums to high-end restaurants. Your data would be considered inconsistent if the engineering team records aquarium models that don’t match the models recorded by the sales team. Another example would be if the monthly profit number is not consistent with the monthly revenue and cost numbers.
How do you measure data consistency?
To test your any data quality dimension, you must measure, track, and assess a relevant data quality metric. In the case of data consistency, you can measure the number of passed checks to track the uniqueness of values, uniqueness of entities, corroboration within the system, or whether referential integrity is maintained. Codd’s Referential Integrity constraint is one example of a consistency check.
How to ensure data consistency
One way to ensure data consistency is through anomaly detection, sometimes called outlier analysis, which helps you to identify unexpected values or events in a data set.
Using the example of two numbers that are inconsistent with one another, anomaly detection software would notify you instantly when data you expect to match doesn’t. The software knows it’s unusual because its machine learning model learns from your historical metadata.
source: metaplane.dev
Introduction
With data breaches on the rise, encryption has never been more important for protecting companies against hackers and cyberattacks.
In a poll of 1,000 business professionals and software developers, nearly 45% say their company Nasdaq show that the number of data breaches grew by more than 68% in 2021, and this number is bound to grow.
Data encryption best practices
Zero trust is a framework for securing infrastructure and data. The security framework assumes that the organization’s network is always at risk so it requires that all users — whether within or outside an organization — be authorized and authenticated before they are granted access to data and applications.
source: techrepublic.com
“A data estate is simply the infrastructure to help companies systematically manage all of their corporate data. A data estate can be developed on-premises, in the cloud or a combination of both (hybrid). From here, organizations can store, manage and leverage their analytics data, business applications, social data, customer relationship systems, functional business and departmental data, internet of things (IoT) and more.”
source: Forbes states in the article ‘ Why The Modern-Day Corporation Should Consider A Data Estate
What is data estate migration and modernization?
A data estate refers to all the data an organization owns, regardless of where it is stored.
source: learn.microsoft.com
8 Strategic Steps To Building A Modern Data Estate
This tells us that the abilities of an organization towards capturing data, data storage, data analysis and searching, sharing, transferring, visualizing, querying, updating of data, as well as compliance and data privacy are no longer a want-to-have.
From A Data Warehouse To A Data Estate
source: timextender.com
link & references: learn.microsoft.com
“A Data Fabric orchestrates disparate data sources intelligently and securely in a self-service manner, leveraging data platforms such as data lakes, data warehouses, NoSQL, translytical, and others to deliver a unified, trusted, and comprehensive view of customer and business data across the enterprise to support applications and insights.”
Properties
A modern Data Fabric comprises multiple layers that work together to meet these needs:
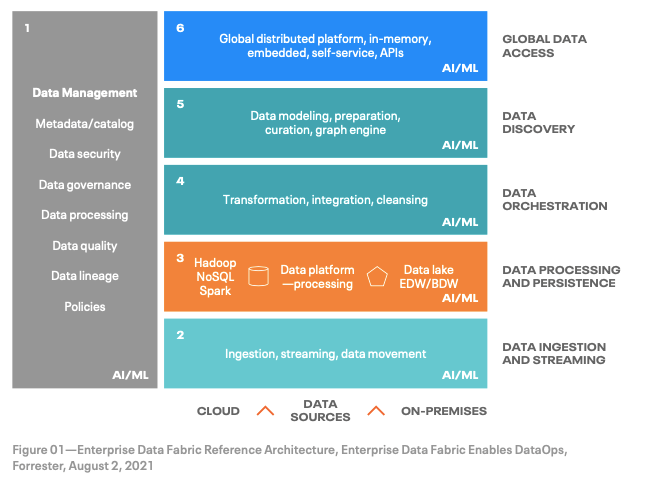
source: cloudera.com
Data governance is a data management discipline. It ensures that the data managed by an organization is available, usable, consistent, trusted and secure. In a majority of companies, IT is the principal steward of data. It is responsible for data governance. But do companies understand the full meaning of data governance? The answer is no.
How to best utilize data governance
What data governance isn’t
Data governance best practices
How to implement data governance best practices in your organization
source: techrepublic.com
Data gravity is the observed characteristic of large datasets that describes their tendency to attract smaller datasets, as well as relevant services and applications. It also speaks to the difficulty of moving a large, “heavy” dataset.
Think of a large body of data, such as a data lake, as a planet, and services and applications being moons. The larger the data becomes, the greater its gravity. The greater the gravity, the more satellites (services, applications, and data) the data will pull into its orbit.
Large datasets are attractive because of the diversity of data available. They are also attractive (i.e. have gravity) because the technologies used to store such large datasets — such as cloud services — are available with various configurations that allow for more choices on how data is processed and used.
The concept of data gravity is also used to indicate the size of a dataset and discuss its relative permanence. Large datasets are “heavy,” and difficult to move. This has implications for how the data can be used and what kind of resources would be required to merge or migrate it.
As business data continues to become an ever increasing commodity, it is essential that data gravity be taken into consideration when designing solutions that will use that data. One must consider not only current data gravity, but its potential growth. Data gravity will only increase over time, and in turn will attract more applications and services.
source: talend.com
Data must be managed effectively to ensure that the information it is providing is accurate, up-to-date, and useful. Data gravity comes into play with any body of data, and as a part of data management and governance, the enterprise must take the data’s influence into account.
Without proper policies, procedures, and rules of engagement, the sheer amount of data in a warehouse, lake, or other dataset can become overwhelming. Worse yet, it can become underutilized. Application owners may revert to using only the data they own to make decisions, leading to incongruous decisions made about a single, multi-owned application.
Data integration is greatly affected by the idea of data gravity — especially the drive to unify systems and decrease the resources wasted by errors or the need to rework solutions. Placing data in one central arena means that data gravity will not collect slowly over time, but rather increase significantly in a short time.
Understanding how the new data gravity will affect the enterprise will ensure that contingencies are in place to handle the data’s rapidly increasing influence on the system. For example, consider how data gravity affects data analysis. Moving massive datasets into analytic clusters is an ineffective — not to mention expensive — process. The enterprise will need to develop better storage optimization that allows for greater data maneuverability.
The problem with data gravity
Data gravity presents data managers with two issues: latency and data non-portability.
source: talend.com
Data integrity is the consistency and correctness of data across its entire life cycle. Learn more about data integrity with the help of this guide.
Clean, healthy data can be a major competitive advantage, especially for businesses that invest the appropriate time and resources into their data management strategies. In the age of Big Data, organizations that harness data effectively and promote data integrity can make better data-driven decisions, improve data quality, and reduce the risk of data loss or corruption.
What is data integrity?
At its most basic level, data integrity is the accuracy and consistency of data across its entire life cycle, from when it is captured and stored to when it is processed, analyzed and used.
Data integrity management means ensuring data is complete and accurate, free from errors or anomalies that could compromise data quality.
Data that has been accurately and consistently recorded and stored will retain its integrity, while data that has been distorted or corrupted cannot be trusted or relied upon for business use.
source: techrepublic.com
Data integrity is important for a number of reasons. However, its importance is best explained with a practical example.
Imagine you are a project manager who is running clinical trials for a new revolutionary drug that will be a game changer in the fight against cancer. You have conducted human trials over the past five years and are convinced you’re ready to move into production.
However, while going through regulatory protocols with the FDA to get your drug to market, they find data integrity issues within the data from your trials — some crucial quality control data is missing.
source: techrepublic.com
Data integrity is a complex and multifaceted issue. Data professionals must be vigilant about the various risks that can compromise data integrity and quality. These include the following:
source: techrepublic.com
source: techrepublic.com
A data lab is a designated data science system that is intended to uncover all that your data has to offer. As a space that facilitates data science and accelerates data experimentation, data labs uncover which questions businesses should ask, then help to find the answer.
The business value of a data lab
Data labs offer advantages that can improve operations and uncover valuable business information. These advantages include:
Though the distinct business advantages will vary between companies, it’s clear that data labs add certain business value to operations as a whole.
source: talend.com
Data matching is the process of comparing data values and calculating the degree to which they are similar. This process is helpful in eliminating record duplicates that usually form over time, especially in databases that do not contain unique identifiers or appropriate primary and foreign keys.
In such cases, a combination of non-unique attributes (such as last name, company name, or street address) is used to match data and find the probability of two records being similar.
Benefits
source: dataladder.com
Data modeling is the process of creating and using a data model to represent and store data. A data model is a representation — in diagrammatic or tabular form — of the entities that are involved in some aspect of an application, the relationships between those entities and their attributes.
The three most common types of data models are.
In relational database design, “relations,” “attributes,” “tuples” and “domains” are some of the most frequently used terms. Additional terms and structural criteria also define a relational database, but the significance of relationships within that structure is what matters. Key data elements (or keys) connect tables and data sets together. Explicit relationships such as parent-child or one-to-one/many connections can also be established.
source: techrepublic.com
source: techrepublic.com
data munging is the initial process of refining raw data into content or formats better-suited for consumption by downstream systems and users.
The term ‘Mung’ was coined in the late 60s as a somewhat derogatory term for actions and transformations which progressively degrade a dataset, and quickly became tied to the backronym “Mash Until No Good” (or, recursively, “Mung Until No Good”).
But as the diversity, expertise, and specialization of data practitioners grew in the internet age, ‘munging’ and ‘wrangling’ became more useful generic terms, used analogously to ‘coding’ for software engineers.
With the rise of cloud computing and storage, and more sophisticated analytics, these terms evolved further, and today refer specifically to the initial collection, preparation, and refinement of raw data.
source: talend.com
With the wide variety of verticals, use-cases, types of users, and systems utilizing enterprise data today, the specifics of munging can take on myriad forms.
source: talend.com
Cloud computing and cloud data warehouses have generally contributed to a massive expansion of enterprise data’s role throughout organizations, and across markets. Data munging is only a relevant term today thanks to the importance of fast, flexible, but carefully governed information, all of which have been the primary benefits of modern cloud data platforms.
Now, concepts such as the data lake and NoSQL technologies have exploded the prevalence, and utility, of self-service data and analytics. Individual users everywhere have access to vast raw data, and are increasingly trusted to transform and analyze that data effectively. These specialists must know how to clean, transform, and verify all of this information themselves.
Whether in modernizing existing systems like data warehouses for better reliability and security, or empowering users such as data scientists to work on enterprise information end-to-end, data munging have never been more relevant concepts.
source: talend.com
Data observability refers to an organization’s ability to understand the health of data throughout the data lifestyle. It helps companies connect the data tools and applications to better manage and monitor data across the full tech stack.
One of the core objectives of data observability is to be able to resolve real-time data issues, such as data downtime, which refers to periods where data is missing, incomplete or erroneous. Such issues with data can be extremely costly for an organization as it can lead to compromised decision-making ability, corrupted data sets, disrupted daily operations and other serious problems.
It is a common misconception that the scope of data observability is only limited to monitoring data quality. That might have been true a few years ago, however, with the increasing complexity of IT systems, the scope of data observantly now includes the entire data value chain.
source: techrepublic.com
Data observability is a must-have for an organization that seeks to accelerate innovation, improve operational efficiency and gain a competitive advantage. The benefits of data observability include better data accessibility, which means the organization has access to uninterrupted data, which is needed for various operational processes and business decision-making.
Another key benefit of data observability is that it allows an organization to discover problems with data before they have a significant negative impact on the business. The real-time data monitoring and alerting can easily be scaled as the organization grows larger or has an increase in workload.
An organization can also benefit from improved collaboration among data engineers, business analysts and data scientists using data observability. The trust in data is also enhanced by data observability, so an organization can be confident in making data-driven business decisions.
Drawbacks to data observability
Data observability has several advantages for an organization, but there are also some downsides and risks. One of the major challenges of data observability is that it is not a plug-and-play solution, which means it requires an organization-level effort for its proper implementation and use. Data observability won’t work with data silos, so there needs to be an effort to integrate all the systems across the organization. This may require all data sources to abide by the same standards.
Another downside of data observability is that it requires a skilled team to get the maximum value from data observability. This means an organization needs to dedicate resources that have the capacity, experience and skills to observe the data. Several data observability tools, provided by various companies, can help but eventually it will be the responsibility of the data engineers to interpret the information, make decisions and determine the root cause of any data-related issues.
There has been significant progress in using machine learning and artificial intelligence to automate some of the data observer roles and responsibilities, however, there is still a long way to go before data observability can be automated
source: techrepublic.com
Data preparation can be complicated. Get an overview of common data preparation tasks like transforming data, splitting datasets and merging multiple data sources.
Data preparation is a critical step in the data management process, as it can help to ensure that data is accurate, consistent and ready for modeling. In this guide, we explain more about how data preparation works and best practices.
Data preparation defined
Data preparation is the process of cleaning, transforming and restructuring data so that users can use it for analysis, business intelligence and visualization. In the era of big data, it is often a lengthy task for data engineers or users, but it is essential to put data in context. This process turns data into insights and eliminates errors and bias resulting from poor data quality.
Data preparation can involve a variety of tasks, such as the following:
While data preparation can be time-consuming, it is essential to the process of building accurate predictive models.
source: techrepublic.com
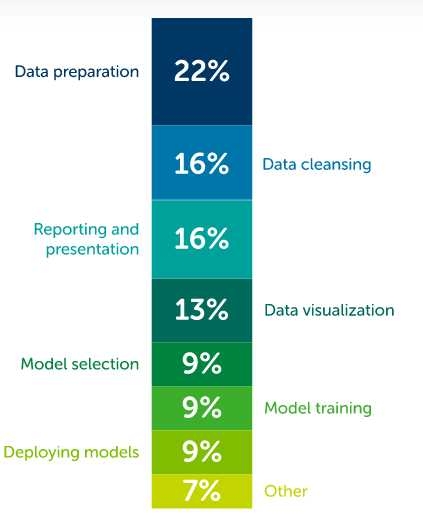
Data scientists spend most of their time preparing data. According to a recent study by Anaconda, data scientists spend at least 37% of their time preparing and cleaning data.
The amount of time spent on menial data preparation tasks makes many data scientists feel that data preparation is the worst part of their jobs, but accurate insights can only be gained from data that has been prepared well. Here are some of the key reasons why data preparation is important:
source: techrepublic.com
The health of your data depends on how well you profile it. Data quality assessments have revealed that only about 3% of data meets quality standards. That means poorly managed data costs companies millions of dollars in wasted time, money, and untapped potential.
Healthy data is easily discoverable, understandable, and of value to the people who need to use it; and it’s something every organization should strive for. Data profiling helps your team organize and analyze your data so it can yield its maximum value and give you a clear, competitive advantage in the marketplace. In this article, we explore the process of data profiling and look at the ways it can help you turn raw data into business intelligence and actionable insights.
Basics of data profiling
Data profiling is the process of examining, analyzing, and creating useful summaries of data. The process yields a high-level overview which aids in the discovery of data quality issues, risks, and overall trends. Data profiling produces critical insights into data that companies can then leverage to their advantage.
More specifically, data profiling sifts through data to determine its legitimacy and quality. Analytical algorithms detect dataset characteristics such as mean, minimum, maximum, percentile, and frequency to examine data in minute detail. It then performs analyses to uncover metadata, including frequency distributions, key relationships, foreign key candidates, and functional dependencies. Finally, it uses all of this information to expose how those factors align with your business’s standards and goals.
Data profiling can eliminate costly errors that are common in customer databases. These errors include null values (unknown or missing values), values that shouldn’t be included, values with unusually high or low frequency, values that don’t follow expected patterns, and values outside the normal range.
reference:
dataladder.com
talend.com
Bad data can cost businesses 30% or more of their revenue. For many companies that means millions of dollars wasted, strategies that must be recalculated, and tarnished reputations. So how do data quality problems arise?
Often the culprit is oversight. Companies can become so busy collecting data and managing operations that the efficacy and quality of data becomes compromised. That could mean lost productivity, missed sales opportunities, and missed chances to improve the bottom line. That’s where a data profiling tool comes in.
Once a data profiling application is engaged, it continually analyzes, cleans, and updates data in order to provide critical insights that are available right from your laptop. Specifically, data profiling provides:
reference: talend.com
In general, data profiling applications analyze a database by organizing and collecting information about it. This involves data profiling techniques such as column profiling, cross-column profiling, and cross-table profiling. Almost all of these profiling techniques can be categorized in one of three ways:
reference: talend.com
Data purging is the process of permanently removing obsolete data from a specific storage location when it is no longer required.
Common criteria for data purges include the advanced age of the data or the type of data in question. When a copy of the purged data is saved in another storage location, the copy is referred to as an archive.
The purging process allows an administrator to permanently remove data from its primary storage location, yet still retrieve and restore the data from the archive copy should there ever be a need. In contrast, the delete process also removes data permanently from a storage location, but doesn’t keep a backup.
In enterprise IT, the compound term purging and archiving is used to describe the removal of large amounts of data, while the term delete is used to refer to the permanent removal of small, insignificant amounts of data. In this context, the term deletion is often associated with data quality and data hygiene, whereas the term purging is associated with freeing up storage space for other uses.
Strategies for data purging are often based on specific industry and legal requirements. When carried out automatically through business rules, purging policies can help an organization run more efficiently and reduce the total cost of data storage both on-premises and in the cloud.
reference:
dataladder.com
techopedia.com
A disaster recovery plan forms a crucial part of any business continuity plan. It is a formal document that outlines in detail how an organization will respond to disasters impacting the business’ IT operations, including:
What are the benefits of a disaster recovery plan?
A disaster recovery plan aims to:
What should a Disaster Recovery Plan include?
source: ontrack.com
References: Put all in the same wrapped line
cleverfiles.com
download.cnet.com
cgsecurity.org
ccleaner.com
crashplan.com
dmde.com
easeus.com
minitool.com
ontrack.com
stellarinfo.com
seriousbit.com
techtarget.com
comparison chart: Put all in the same wrapped line
cleverfiles.com
handyrecovery.com
The practice of preparing for downtime is called disaster recovery (DR) planning.
A disaster recovery plan consists of the policies and procedures that your business will follow when IT services are disrupted. The basic idea is to restore the affected business processes as quickly as possible, whether by bringing disrupted services back online or by switching to a contingency system.
Your disaster recovery plan should take into account the following:
At the centre of most DR plans are two all-important KPIs, which are typically applied individually to different IT services: recovery point objective (RPO) and recovery time objective (RTO). Don’t be confused by the jargon, because they’re very simple:
Structuring the perfect disaster recovery plan
Even a small business DR plan can be a lengthy and complex document. However, most follow a similar structure, encompassing definitions, duties, step-by-step response procedures and maintenance activities. In our template, we’ve used the following outline:
Do not forget these suggestions:
What is a disaster recovery plan, and why do you need one?
A step-by-step guide to disaster recovery planning
If you’re interested in ensuring Ontrack is part of your disaster recovery plan, talk to one of our experts today.
source: resources.ontrack.com
reference:
Put all in the same wrapped line
ontrack.com
iso-docs.com
disasterrecoveryplantemplate.org
microfocus.com
easeus.com
ibm.com
solutionsreview.com
A data silo is a collection of data held by one group that is not easily or fully accessible by other groups in the same organization. Finance, administration, HR, marketing teams, and other departments need different information to do their work. Those different departments tend to store their data in separate locations known as data or information silos, after the structures farmers use to store different types of grain. As the quantity and diversity of data assets grow, data silos also grow.
Data silos may seem harmless, but siloed data creates barriers to information sharing and collaboration across departments. Due to inconsistencies in data that may overlap across silos, data quality often suffers. When data is siloed, it’s also hard for leaders to get a holistic view of company data.
In short, siloed data is not healthy data. Data is healthy when it’s accessible and easily understood across your organization. If data isn’t easy to find and use in a timely fashion, or can’t be trusted when it is found, it isn’t adding value to analyses and decision-making processes. An organization that digitizes without breaking down data silos won’t access the full benefits of digital transformation. To become truly data-driven, organizations need to provide decision-makers with a 360-degree view of data that’s relevant to their analyses.
Data analysis of enterprise-wide data supports fully informed decision-making, and a more holistic view of hidden opportunities — or threats! Plus, siloed data is itself a risk. Data that is siloed makes data governance impossible to manage on an organization-wide scale, impeding regulatory compliance and opening the door to misuse of sensitive data.
To better understand if data silos are holding back your potential for holistic data analysis, you’ll need to learn more about where data silos come from, how they hinder getting the full benefit of data, and your options for data integration to get rid of data silos.
source: talend.com
Data silos occur naturally over time, mirroring organizational structures. As each department collects and stores its own data for its own purposes, it creates its own data silo. Most businesses can trace the problem to these causes of data silos:
4 ways data silos are silently killing your business
Each department exists to support a common goal. While departments operate separately, they are also interdependent. At least some of the internal data that the finance department creates and manages, for example, is relevant for analysis by administration and other departments.
Here are four common ways data silos hurt businesses:
source: talend.com
The solutions to silos are technological and organizational. Centralizing data for analysis has become much faster and easier in the cloud. Cloud-based tools streamline the process of gathering data into a common pool and format for efficient analysis. What once took weeks, months, or years can now be accomplished in days or hours.
The cloud and the future of data storage
Tearing down data silos
Data silos undermine productivity, hinder insights, and obstruct collaboration. But silos cease to be a barrier when data is centralized and optimized for analysis. Cloud technology has been optimized to make centralization practical.
source: talend.com
Data stewardship is the implementation of the procedures, roles, policies and rules set by the data governance framework. This includes people, technology and processes. Data stewards or a team of data stewards are tasked with the responsibility of protecting data assets of the entire organization, department, business unit or a small set of data. They are also tasked with the implementation of data governance initiatives, improving the adoption of data policies and procedures, and ensuring users are held accountable for the data in their care.
What are the similarities and differences between data stewardship and data governance?
As data stewardship is effectively a branch of data governance, they share some common goals of protecting data, making it more manageable and getting the maximum value from it. The ultimate goal of data governance and data stewardship is to have fully governed data assets.
Although these two terms are used interchangeably, there are distinct differences. While data governance deals with policies, processes and procedures, data stewardship is only concerned with the procedures. This means that data stewards are not responsible for creating or writing policies or processes, their job is to interpret and implement them on a day-to-day basis. This requires data stewards to have technical familiarity with the data and the systems that use the data, and business acumen to understand integration of data with business processes and outcomes.
Data stewardship best practices
source: techrepublic.com
Data transformation is the process of converting, cleansing, and structuring data into a usable format that can be analyzed to support decision making processes, and to propel the growth of an organization
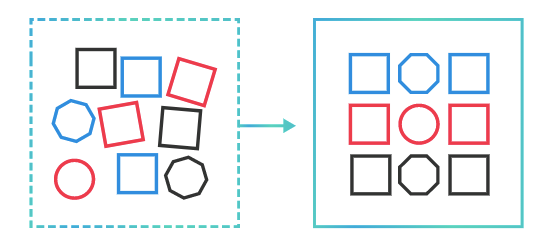
Data transformation is used when data needs to be converted to match that of the destination system. This can occur at two places of the data pipeline. First, organizations with on-site data storage use an extract, transform, load, with the data transformation taking place during the middle ‘transform’ step.
Source: tibco.com
The Data Vault is a hybrid data modeling methodology providing historical data representation from multiple sources designed to be resilient to environmental changes. Originally conceived in 1990 and released in 2000 as a public domain modeling methodology, Dan Linstedt, its creator, describes a resulting Data Vault database as:
“A detail oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business. It is a hybrid approach encompassing the best of breed between 3NF and Star Schemas. The design is flexible, scalable, consistent and adaptable to the needs of the enterprise.”
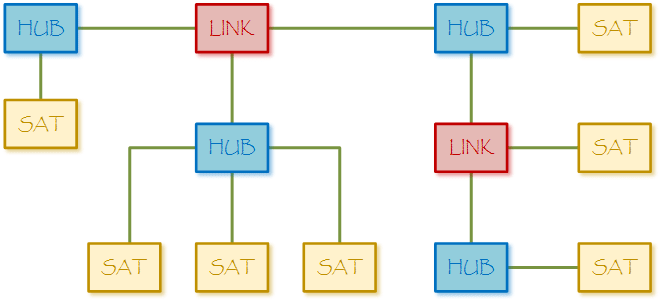
Focused on the business process, the Data Vault as a data integration architecture, has robust standards and definitional methods which unite information in order to make sense if it. The Data Vault model is comprised of three basic table types:
There are several key advantages to the Data Vault approach:
Simply put, the Data Vault is both a data modeling technique and methodology which accommodates historical data, auditing, and tracking of data.
“The Data Vault is the optimal choice for modeling the EDW in the DW 2.0 framework”
Conclusion
source: talend.com
Data wrangling is the process of removing errors and combining complex data sets to make them more accessible and easier to analyze.
A data wrangling process, also known as a data munging process, consists of reorganizing, transforming and mapping data from one “raw” form into another in order to make it more usable and valuable for a variety of downstream uses including analytics.
Data wrangling can be defined as the process of cleaning, organizing, and transforming raw data into the desired format for analysts to use for prompt decision-making. Also known as data cleaning or data munging, data wrangling enables businesses to tackle more complex data in less time, produce more accurate results, and make better decisions. The exact methods vary from project to project depending upon your data and the goal you are trying to achieve. More and more organizations are increasingly relying on data wrangling tools to make data ready for downstream analytics.
Data has the potential to change the world. But before it does, it has to go through a fair amount of processing to be ready for analysis. A critical step in this processing is data wrangling. Data wrangling is a non-technical term used to describe the crucial cleaning and sorting step of data analysis. Specifically, data wrangling is a process that manually transforms and maps raw data into various formats based on specific use cases.
While the process is not considered glamorous, data wrangling is the backbone behind understanding data. Without it, a business’s data is nothing more than an unorganized mess — difficult to read, impossible to access, and unlikely to be analyzed in a useful manner. It’s no surprise, then, that Data scientists dedicate 80% of their time to data wrangling.
See also data munging
source:
simplilearn.com
talend.com
Knowledge Base Dedicated Page
Blog Dedicated Page
© 2024 Altos Web Solutions. All Rights Reserved!